SQL and python
Overview
Teaching: 90 min
Exercises: 0 minQuestions
What is SQL?
How can I use SQL to enhance my workflow?
How do SQL and Python work together?
What is an ORM?
Objectives
Understand relational databases
Learn some basic SQL commands
Use Python and SQL to work with a database
Review a few Python ORM modules
What is SQL?
SQL (or “sequel”) is a language developed for managing data in a relational database management system (RDBMS). A relational database can be thought of as a supped up version of an excel workbook or csv file, as the data is stored in tables composed of rows and columns. The tables within a database can contain links (relationships) between them, and constraints on the data within. SQL is then a language that lets you create a database structure (schema), add/modify the data within, and query the database.
You may be using a set of .csv or text files (a.k.a “flat files”) to store your data, and then have a naming system in place to help you remember where all the data are located on your computer. You might even have some scripts written that will help you update or locate information within your directory/file structure. A database is one part a data storage system, and one part a data management system and can replace whatever system you may be using at the moment. Advantages of using a database to store and manage our data include:
- Avoid data isolation
- Data stored in multiple places can often be stored in multiple formats, making access to the data difficult.
- A defined data structure (schema) ensures that your data are stored in consistent formats
- Data integrity
- Storing data in multiple places can lead to inconsistencies when the data are being modified
- Some data have constraints on allowable values, which need to be imposed when updating the data
- Atomic operations
- Updating data in multiple places (such as moving funds from one department to another) needs to happen all at once or not at all.
- Having an update break mid-way through and having funds withdrawn from one department but not deposited into another is unacceptable.
- Atomic operations ensure that the entire operation is either applied successfully, or nothing is changed.
- Concurrent-access
- Similar to the above, when multiple programs or people are updating data at the same time it is important to ensure that these updates don’t clash with each other.
- A common issue is if two programs try to update a value by adding 1 to it, if they both read a value of 5 at the same time, then add one and then write a 6, the end result is an increment of just 1 rather than 2.
- A DBMS will manage updates to data to ensure that none of these race conditions cause errors.
- Security
- A DBMS has more fine grained access control than a flat file system
- A flat file system can restrict access based on file/directory to users or groups
- A DBMS can restrict access based on tables or even individual rows, and can allow users to only see aggregated results.
- SQL as a data management and retrieval language
- Accessing data is done via SQL eliminating the need for custom access/update scripts.
- The universality of SQL means that your programs can interface with many different databases using a common language.
Database Structure vs content
A database system separates the structure of your data (the schema) from the content. Before you can add data into your system you need to have a place for it to go. The schema of a database describes each table, it’s columns, constraints on the columns, and relationships between the different tables. Additionally a schema can define a primary key (think index) for each row, which describes what must be unique between rows. That is, each row has a primary key that is different from all other rows. A primary key can be simply an integer row number (like a student/staff ID), but can be a combination of existing columns (first name, last name, date of birth).
In the example below we have six tables defined each with a primary key that is <table name> id, some columns with given data formats, and some relationships between the tables.
The relationships below are things like “the teacher id in the subject/teacher table is a link to the teacher id in the teacher table”.
A teacher can be associated with multiple subjects, and a single subject can be taught by multiple teachers.

The SQLite reference page is a good resource for a minimal implementation of the SQL language. The following commands operate on the database schema as they describe the structure and relationship between the tables:
- ALTER TABLE
- CREATE TABLE
- DROP TABLE
The following commands operate on tables:
- DELETE
- INSERT
- SELECT
- UPDATE
Note that in most cases you cannot ALTER/DROP a table if the table contains data. That is - schema operations are only permitted on empty tables.
Explore the SQLite syntax diagrams
Head to the SQLite online documentation and view the syntax diagram for the “CREATE TABLE” query.
Using the SQLite reference above we can create the Teachers table above like this:
CREATE TABLE Teachers (
"teacher id" int,
"first name" varchar,
"last name" varchar,
PRIMARY KEY ("teacher id")
);
A SQL command is typically terminated with the ; character, and white space in the command is ignored.
This means that you are free to use multi-line statements and indenting as above, to keep your code readable.
Make the Subjects relation
- Head to sqliteonline.com.
- Copy the above commands and execute them.
- Note on the left panel that you’ll have a new table called “Teachers” which you can click on to see the schema.
- Using the above template, and the SQLite reference, write a similar command to create the
Subjectstable.Answer
CREATE TABLE Subjects ( "subject id" integer, "title" varchar, PRIMARY KEY ("subject id") );
And we can create table relations in the Subject/teacher table like this:
CREATE TABLE "Subject/teacher" (
"subject id" integer,
"teacher id" integer,
"group id" integer,
FOREIGN KEY ("subject id") REFERENCES "Subjects.subject id",
FOREIGN KEY ("teacher id") REFERENCES "Teachers.teacher id",
/*FOREIGN KEY ("group id") REFERENCES "Groups.group id",*/
PRIMARY KEY ("subject id", "teacher id", "group id")
);
The extensive use of quoting above is required sine our table/column names contain spaces and the / character.
It’s good practice to avoid such characters (and use only lower case) such that you could type subject.subject_id etc.
If you want a table or column name that clashes with a reserved word (eg dec) then you need to quote it every time you use it.
Note: The /* and */ have been used to comment out a line that refers to a table that we haven’t created, to stop SQLite from complaining.
Foreign Keys with SQLite
By default SQLite doesn’t enforce foreign key constraints - it will let you create broken links. To instruct SQLite to play nice you should do the following:
PRAGMA foreign_keys = ON;
Interacting with the database contents
Once we have the structure in place, we can begin to add content to our database. This is where the table operations come in: DELETE, INSERT, SELECT, UPDATE.
To add data we use the INSERT operation like this:
INSERT INTO Teachers (
"teacher id",
"first name",
"last name"
) VALUES (
007,
"James",
"Bond"
);
To see the results of our operation we should use a SELECT query to view the table:
SELECT * FROM Teachers;
The * is a short cut for “all columns”.
We should see output like this from the command line:
007|James|Bond
Add yourself as a Teacher
- Copy and execute the above INSERT operation on your database
- Modify the statement to add yourself to the database with a different teacher id
- View the Teachers table using a SELECT query.
- DELETE the James Bond example by referencing their teacher id.
- Confirm that the deletion worked by running another SELECT query.
Add more data to our database:
Run the following commands insert more data int our tables:
INSERT INTO Subjects ("subject id", "title") VALUES (101, "Astronomy"); INSERT INTO Subjects ("subject id", "title") VALUES (102, "Math"); INSERT INTO Subjects ("subject id", "title") VALUES (103, "Physics"); INSERT INTO Subjects ("subject id", "title") VALUES (201, "Electrodynamics"); INSERT INTO Teachers ("teacher id", "first name", "last name") VALUES (1234, "Vera", "Rubin"); INSERT INTO "Subject/teacher" ("subject id","teacher id","group id") VALUES (101,1234,1); INSERT INTO "Subject/teacher" ("subject id","teacher id","group id") VALUES (102,1234,1);Also add yourself as a teacher for one of the remaining subjects
Making use of the table relations
We have relationships defined between the tables, which means that we can ask questions like: “Who teaches which subjects?”.
To do this we need to JOIN two tables together based on some criteria:
SELECT "first name", "last name", "subject id"
FROM "Subject/teacher"
NATURAL JOIN Teachers;
Since we have a foreign key relationship between the two tables the NATURAL JOIN assumes we want to match rows in the “Subject/teacher” table with those in the “Teachers” table based on this relationship.
If we didn’t have this explicit relationship defined in the schema we’d have to do the following:
SELECT "first name", "last name", "subject id"
FROM "Subject/teacher" AS st
JOIN Teachers AS t
ON st."teacher id"=="t"."teacher id" ;
Note: we can use the AS clause to rename a table in our query to make life easier.
We can do the same for the columns to rename the column headers
If we wanted to list the subject title instead of just the subject id, we would need to join a third table to get that information.
Join three tables
Create a query that will output the teacher’s “first name”, “last name”, and the subject “title”.
Solution
SELECT "first name", "last name", "title" FROM "Subject/teacher" NATURAL JOIN Subjects NATURAL JOIN Teachers;
As well as selecting data we can filter data using the WHERE clause.
For example we can choose just the first year subjects using a filter on the subject id:
SELECT * FROM Subjects WHERE "subject id" < 200;
Or we could find all teachers who have an ‘e’ in their first name:
SELECT * from Teachers WHERE "first name" LIKE "%e%";
Doing more than just data selection
SQL is much more than just a language for retrieving data, we can also aggregate and transform data as part of our selection process.
For example if we wanted to see how many subjects a teacher was responsible for we could use the COUNT function for this:
SELECT count(*) AS "Subjects Taught", "teacher id" FROM "Subject/teacher" WHERE "Teacher id" == 12;
Even better, we can do this for all the teachers using the GROUP BY clause:
SELECT count(*) AS "Subjects Taught", "teacher id" FROM "Subject/teacher" GROUP BY "teacher id";
The WHERE clause filters the input of a query, but the HAVING clause will filter the output.
Thus we could do the following to look at all the teachers who teach more than one class:
SELECT count(*) AS "Subjects Taught", "teacher id" FROM "Subject/teacher" GROUP BY "teacher id" HAVING "Subjects Taught">1;
Database flavours
Everything that we have learned above has been using an SQLite database. This database was chosen because it implements nearly all of the SQL features that ar part of the ISO specification. As a result everything that you have learned is applicable to other RDBMS software. Different software providers provide additional capability or operations designed to make the database more secure, faster, or more easily usable. Data base systems are big business and can often be tailored to a specific industry or use case, and are often proprietary. An extensive list is on wikipedia, however some commonly used database systems are:
- SQLite
- Lightweight, fast, reliable.
- Stores all tables in a single file
- Doesn’t have security or permissions
- PostgreSQL
- “The World’s Most Advanced Open Source Relational Database”
- Available on nearly any OS
- MySQL
- Open source
- Developed by Oracle
- Available on nearly any OS
- Microsoft SQL Server
- Only available on Linux/Windows servers
- Not free
At some level you can migrate your data between any of these systems, though it can be extremely painful to do so. Migrating from SQLite to some other system is the least painful, and so many developers will being their projects using an SQLite backend and then migrate to something else when the need arises. Alternatively, SQLite is often used as a quick and easy to deploy database as part of a testing or development environment.
Using databases from Python
There are two main ways to work with databases in python:
- libraries that provide an interface for a given database and you manage the database yourself
- Object Relational Mappers (ORMs) which create/manage the database for you, and provide you with an SQL free interface to the database.
SQL libraries in python
| library | database supported |
|---|---|
| sqlite3 | SQLite |
| psycopg2 | PostgreSQL |
| MySQL-Python | MySQL |
| pyodbc | MS SQL Server |
| SQLAlchemy | multiple |
Each of the above libraries have effectively the same architecture for how they give you access to the underlying database. You create a connection object to connect to the database, and from this you create a cursor. The cursor is then used to execute queries in the database. It is possible for you to have multiple cursors in the same connection/database running at the same time, for example if you have a program that uses multiple threads or processes.
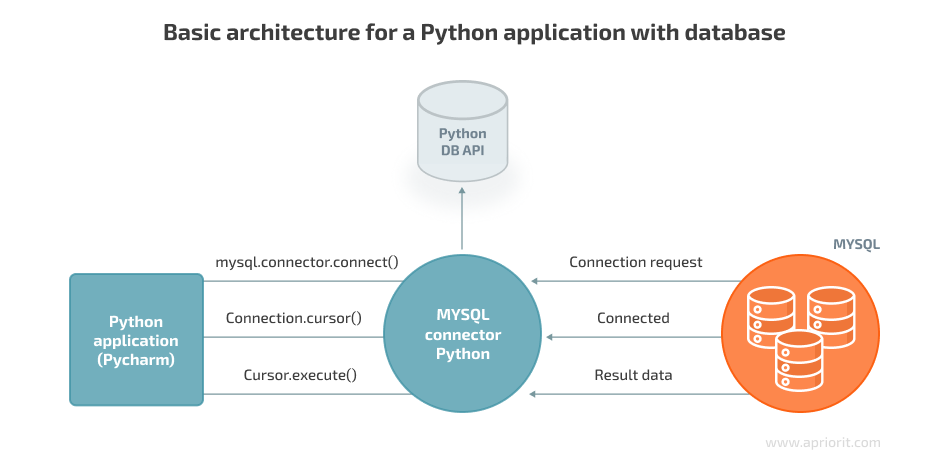
Let’s look at an example using sqlite:
import sqlite3
# Create a connection to the database
# if no file exists then an empty db is created
conn = sqlite3.connect("test.db")
# Create a cursor object
cur = conn.cursor()
# Now use the cursor object for all our SQL commands
# Create a table
cur.execute("""
CREATE TABLE Teachers (
"teacher id" int,
"first name" varchar,
"last name" varchar,
PRIMARY KEY ("teacher id")
)""")
cur.execute("""
CREATE TABLE Subjects (
"subject id" integer,
"title" varchar,
PRIMARY KEY ("subject id")
)""")
cur.execute("""
CREATE TABLE "Subject/teacher" (
"subject id" integer,
"teacher id" integer,
"group id" integer,
FOREIGN KEY ("subject id") REFERENCES "Subjects.subject id",
FOREIGN KEY ("teacher id") REFERENCES "Teachers.teacher id",
/*FOREIGN KEY ("group id") REFERENCES "Groups.group id",*/
PRIMARY KEY ("subject id", "teacher id", "group id")
)""")
# Insert some data
cur.execute("""
INSERT INTO Teachers (
"teacher id",
"first name",
"last name"
) VALUES (
007,
"James",
"Bond"
)""")
cur.execute('INSERT INTO Subjects ("subject id", "title") VALUES (101, "Astronomy")')
cur.execute('INSERT INTO Subjects ("subject id", "title") VALUES (102, "Math")')
cur.execute('INSERT INTO Subjects ("subject id", "title") VALUES (103, "Physics")')
cur.execute('INSERT INTO Subjects ("subject id", "title") VALUES (201, "Electrodynamics")')
cur.execute('INSERT INTO Teachers ("teacher id", "first name", "last name") VALUES (1234, "Vera", "Rubin")')
cur.execute('INSERT INTO "Subject/teacher" ("subject id","teacher id","group id") VALUES (101,1234,1)')
cur.execute('INSERT INTO "Subject/teacher" ("subject id","teacher id","group id") VALUES (102,1234,1)')
# Commit changes (save to file)
conn.commit()
# Execute a SQL query
cur.execute("SELECT * FROM Teachers")
result = cur.fetchall()
print(result)
# Close the connection
conn.close()
If we had the subject id and titles in some python lists then it would be nicer to write a loop for inserting the data. Note that when doing this you should avoid using python to preformat the strings, and instead use a parametrized query like this:
for id, title in zip( [101,102,103],["Astronomy", "Math", "Physics"]):
cur.execute('INSERT INTO Subjects ("subject id", "title") VALUES (?, ?)', (id,title))
The reason is that it will allow the library to deal with all the escape characters and type conversion, drastically reducing the chances of an SQL injection attack being successful.

These libraries are great if you have simple databases to manage, or if you are just reading from an existing database. If you have more complex databases to manage then it’s often better to work with an object relational mapper or ORM.
Extra: Python ORMs
ORMs provide an on a relational database that allows you to write Python code instead of SQL. Developers can use the programming language they are comfortable with to work with a database instead of writing SQL statements or stored procedures.
For example if we want to find all the first year subjects in our database we could write:
SELECT * FROM Subject WHERE "subject id" < 200;
But with the aid of an ORM we would write something like this
first_yr_subjects = Subject.objects.filter(subject_id < 200)
Another advantage of an ORM is that you can easily change the backed database you are using without having to re-write all your code. The ORM translates your object/function calls into SQL code, making use of whatever functionality is available in the backend database.
Some common Python ORMs include:
- DJango
- SQLAlchemy (yes it’s an ORM as well)
- PonyORM
- Peewee
DJango also include extra features like a web server and many plug-ins, making it a go-to solution for many web developers.
An ORM not only allows you to query the data with ease, but also to create the database schema using a Python object syntax like this:
class Book(models.Model):
"""Model representing a book (but not a specific copy of a book)."""
title = models.CharField(max_length=200)
author = models.ForeignKey('Author', on_delete=models.SET_NULL, null=True)
summary = models.TextField(max_length=1000, help_text='Enter a brief description of the book')
isbn = models.CharField('ISBN', max_length=13, unique=True, help_text='13 Character ISBN number')
Key Points
Databases have many benefits over flat files
SQL is a powerful data selection and retrieval language
An ORM gives you a ‘pythonic’/object based interface for your database