Optimization
Overview
Teaching: 30 min
Exercises: 30 minQuestions
How can I optimize my code?
What am I even optimizing for?
Objectives
Review the different resources we can optimize for
Understand the optimization loop
Make our example code run at least a little faster
Scope your optimization work
When we are engaged in optimization there are a few things we should do first:
- Understand what the problem is
- Measure the current state of things (benchmark + first profile)
- Have a target in mind for what is “good enough”
When thinking about the problem, remember that your code doesn’t run in isolation. It runs as part of a larger workflow, that includes other pieces of code as well as non-automated things like researcher thinking time. Consider your entire workflow, and how much time is spent on waiting for code to run vs you analyzing results. If you have other useful work that can be done while your code runs, then do that, it’ll be time well spent.
Amdahl’s Law:
- System speed-up limited by the slowest component.
Paul’s rule of thumb:
- You are the slowest component.
Therefore:
- Focus on reducing your active interaction time,
- then on your total wait time,
- then on cpu time.
In parallel computing we’ll explore ways of making your work complete sooner, without making it run faster! Another way of making your code run faster can be to just buy a faster computer, though this isn’t always an option for everyone).
A reason to confirm that we need to optimize our code is that we want to avoid premature optimization:

Good coding practices can lead to more performant code from the outset. This is not wasted time.
Remember also that you cannot can’t optimize to zero. There will always be a minimum amount of time that your work will take to do, and you will only ever approach this minimum asymptotically. At first you’ll get 2-3 or even 10x speed increases for moderate effort, but as you keep going, you’ll end up spending a day writing unreadable code just for that 0.1% gain. Don’t be a speed addict, know when to quit!
Leveraging the work of others
There are a lot of python packages that are designed, directly or indirectly, to provide optimized python code. For example:
- NumPy
- The fundamental package for scientific computing with Python
- SciPy
- Fundamental algorithms for scientific computing in Python
- extends upon Numpy to provide additional data structures and algorithms
- Numba
- an open source JIT compiler that translates a subset of Python and NumPy code into fast machine code.
- Dask
- library for parallel computing in Python, with a focus on workflows and big data processing
- Taichi
- a domain-specific language embedded in Python that helps you easily write portable, high-performance parallel programs
- Cython
- an optimising static compiler for both the Python programming language and the extended Cython programming language
- write python code, convert it to c, compile, and run
- PyPy
- A fast, compliant alternative implementation of Python
- Not python modules will work in pypy, but many of the main one will
- pandas
- a fast, powerful, flexible and easy to use open source data analysis and manipulation tool, built on top of the Python programming language.
These packages can provide significant performance increases, often by implementing parallel processing under the hood, without you having to write or manage any of the parallel computing components.
The Optimization Loop
Using scalene we’ll re-run our initial profiling to ensure the results are consistent with the profiling we did in the previous lesson.
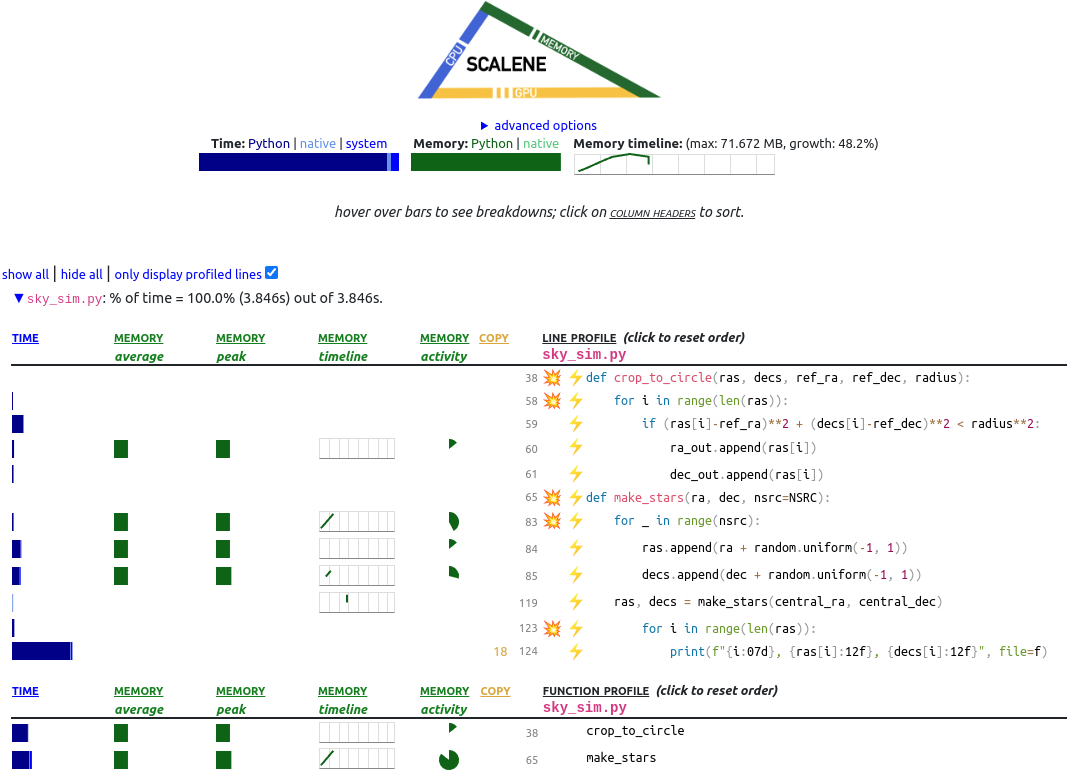
We should see the I/O is still the main bottleneck and as per Amdahl’s law we should fix that first.
One idea we can try first is to speed up the I/O (system) time by utlising the NumPy python module we are already using in several places.
NumPy has a way to quickly store data arrays into a file using the savetxt function.
For our exercise, we’ll create a new file in our mymodule directory and call it sky_sim_opt.py and copy the contents of your sky_sim.py into sky_sim_opt.py.
Using NumPy we can change the main function which runs all the functions to create our sources and then saves the csv file. To do this we’ll turn the ras and decs variables into
# Make sure to include an import to numpy as np at the top of your file.
import numpy as np
...
if __name__ == "__main__":
parser = skysim_parser()
options = parser.parse_args()
if None in [options.ra, options.dec]:
central_ra, central_dec = get_radec()
else:
central_ra = options.ra
central_dec = options.dec
ras, decs = make_stars(central_ra, central_dec)
# Turn our list of floats into NumPy arrays
ras = np.array(ras)
decs = np.array(decs)
# We stack the arrays together, and use savetxt with a comma delimiter
np.savetxt(options.out, np.stack((ras, decs), axis=-1), delimiter=",")
print(f"Wrote {options.out}")
Let’s rerun scalene with sky_sim_opt.py
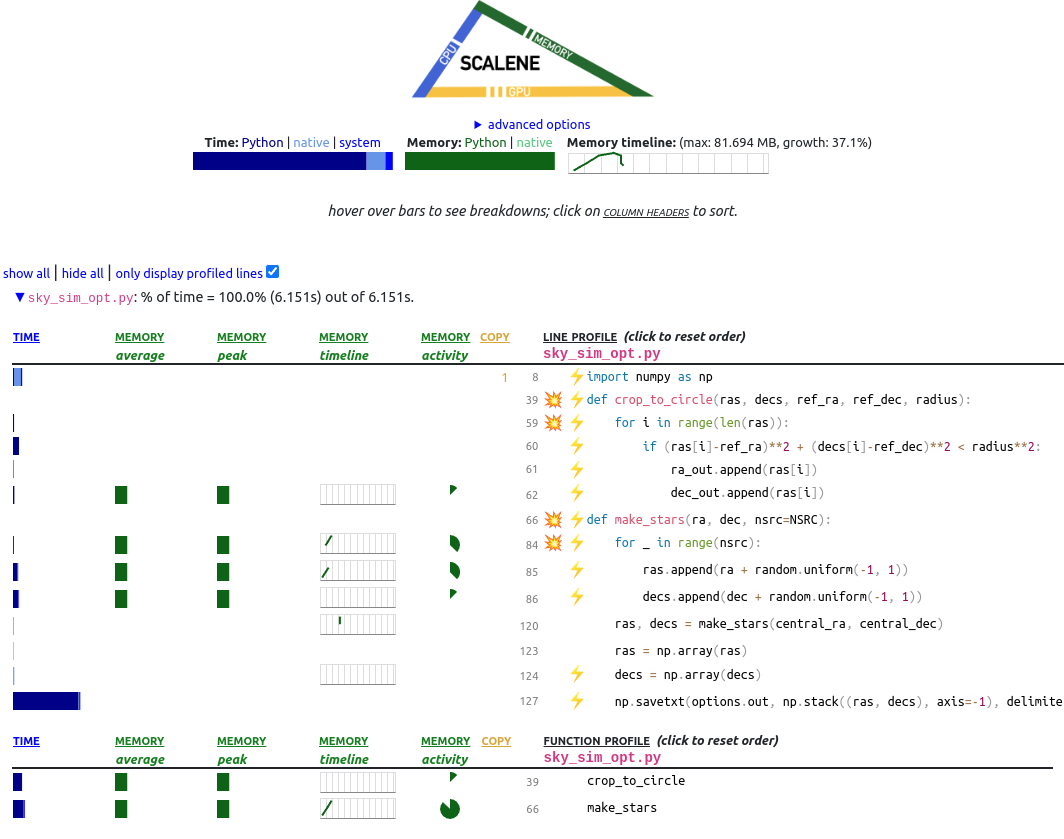
That is an unfortunate result, however we have increased the time spent in native which is a good thing. At the moment we are converting our list of floats into NumPy arrays, this has a cost of copying the lists from Python memory to the memory used for the native array in NumPy. The copying of arrays from Python to NumPy generally means it’s recommended that you start with NumPy arrays and then do operations on the arrays themselves using NumPy vectorized functions (we will cover vectorization more in parallel computing).
To initialize our arrays, most would suggest we initialize with an array containing only zeros using np.zeros, however because we are filling the array with values later, we can use a slightly faster operation np.empty. To show the difference between np.zeros and np.empty we can use the ipython %timeit magic. If you installed Python through Anaconda, ipython should already be installed, otherwise run pip install ipython. Inside your bash terminal run ipython, and run the following commands:
import numpy as np
%timeit np.zeros(1000000)
%timeit np.empty(1000000)
Python 3.8.16 | packaged by conda-forge | (default, Feb 1 2023, 16:01:55)
Type 'copyright', 'credits' or 'license' for more information
IPython 8.11.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]: import numpy as np
In [2]: %timeit np.zeros(1000000)
317 µs ± 596 ns per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
In [3]: %timeit np.empty(1000000)
278 ns ± 0.92 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
From the result of %timeit, we can see np.empty is measured in nanoseconds compared to microseconds for zeros, you’ll also notice np.empty completed 1000x more loops than np.zeros in the same amount of time, impressive! When comparing NumPy functions and functions that do similar things in general tools like %timeit are very useful. Tools like %timeit allows us to benchmark snippets of code to ensure our ideas of optimization do make sense (because having ideas is good, but testing them is even better).
Although, as we look further into the NumPy documentation for more ideas we find the np.random.uniform function. This allows us to create a NumPy array of random values between a low and a high value of a certain size if we so wish. Using np.random.uniform we eliminate the comparatively slower Python for loop, and have make_stars run much faster.
Employing np.random.uniform change alongside our NumPy savetxt we get the following sky_sim_opt:
#! /usr/bin/env python
"""
Simulate a catalog of stars near to the Andromeda constellation
"""
import argparse
import math
import numpy as np
import random
NSRC = 1_000_000
def get_radec():
"""
Generate the ra/dec coordinates of Andromeda
in decimal degrees.
Returns
-------
ra : float
The RA, in degrees, for Andromeda
dec : float
The DEC, in degrees for Andromeda
"""
# from wikipedia
andromeda_ra = '00:42:44.3'
andromeda_dec = '41:16:09'
degrees, minutes, seconds = andromeda_dec.split(':')
dec = int(degrees)+int(minutes)/60+float(seconds)/3600
hours, minutes, seconds = andromeda_ra.split(':')
ra = 15*(int(hours)+int(minutes)/60+float(seconds)/3600)
ra = ra/math.cos(dec*math.pi/180)
return ra, dec
def crop_to_circle(ras, decs, ref_ra, ref_dec, radius):
"""
Crop an input list of positions so that they lie within radius of
a reference position
Parameters
----------
ras,decs : list(float)
The ra and dec in degrees of the data points
ref_ra, ref_dec: float
The reference location
radius: float
The radius in degrees
Returns
-------
ras, decs : list
A list of ra and dec coordinates that pass our filter.
"""
ra_out = []
dec_out = []
for i in range(len(ras)):
if (ras[i]-ref_ra)**2 + (decs[i]-ref_dec)**2 < radius**2:
ra_out.append(ras[i])
dec_out.append(ras[i])
return ra_out, dec_out
def make_stars(ra, dec, nsrc=NSRC):
"""
Generate NSRC stars within 1 degree of the given ra/dec
Parameters
----------
ra,dec : float
The ra and dec in degrees for the central location.
nsrc : int
The number of star locations to generate
Returns
-------
ras, decs : list
A list of ra and dec coordinates.
"""
ras = np.random.uniform(ra - 1, ra + 1, size=nsrc)
decs = np.random.uniform(dec - 1, dec + 1, size=nsrc)
# apply our filter
ras, decs = crop_to_circle(ras, decs, ra, dec, 1)
return ras, decs
def skysim_parser():
"""
Configure the argparse for skysim
Returns
-------
parser : argparse.ArgumentParser
The parser for skysim.
"""
parser = argparse.ArgumentParser(prog='sky_sim', prefix_chars='-')
parser.add_argument('--ra', dest='ra', type=float, default=None,
help="Central ra (degrees) for the simulation location")
parser.add_argument('--dec', dest='dec', type=float, default=None,
help="Central dec (degrees) for the simulation location")
parser.add_argument('--out', dest='out', type=str, default='catalog.csv',
help='destination for the output catalog')
return parser
if __name__ == "__main__":
parser = skysim_parser()
options = parser.parse_args()
if None in [options.ra, options.dec]:
central_ra, central_dec = get_radec()
else:
central_ra = options.ra
central_dec = options.dec
ras, decs = make_stars(central_ra, central_dec)
# now write these to a csv file for use by my other program
with open(options.out,'w') as f:
print("id,ra,dec", file=f)
for i in range(NSRC):
print(f"{i:07d}, {ras[i]:12f}, {decs[i]:12f}", file=f)
print(f"Wrote {options.out}")
You’ll notice the original code for writing a CSV is back.
Upon further investigation after changing to np.random.uniform we found that np.savetxt was slower than the code we had written previously.
This is a quick lesson in Python is a high level language and while we assume that packages such as NumPy always have faster functions, this isn’t always true as we don’t know what’s happening under the hood. This is why we described optimization as a loop, you’ll try ideas, some will work, others won’t, this is a natural part of the process. Sometimes though, code can’t be made faster quickly as we found out in the case here, we tried to find a faster way to write a CSV, and there probably is one, but we have declared it’s fast enough for our use case.
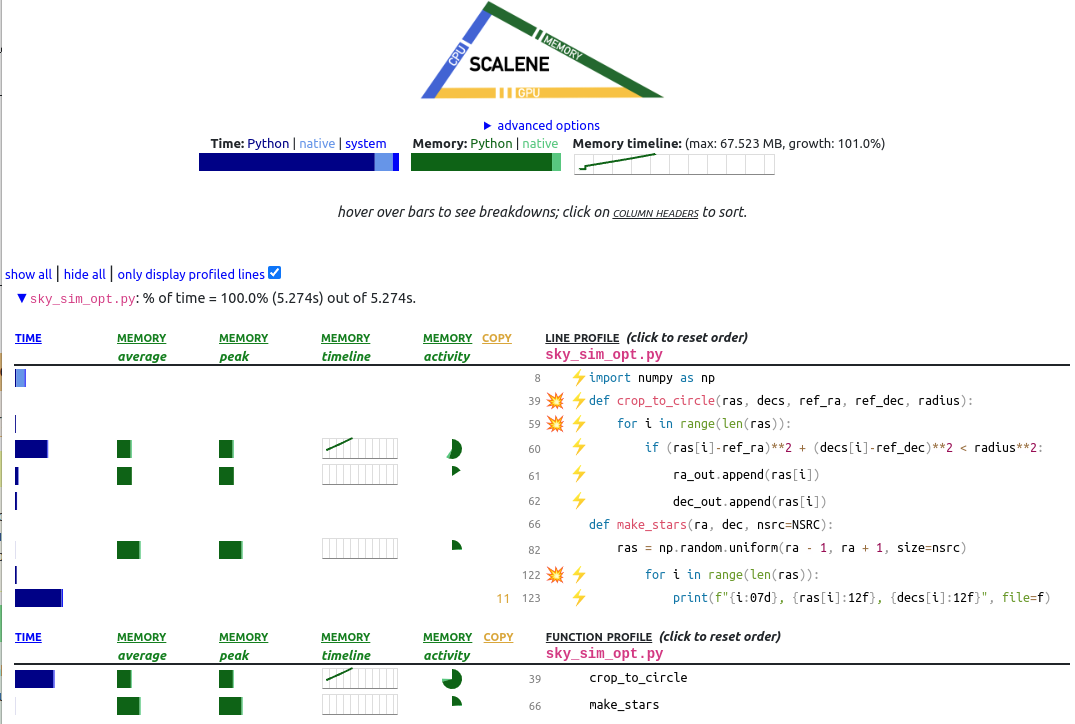
It’s time for you to see if you can make
sky_sim_optfasterIn your own time, feel free to try and see if you can optimize
sky_sim_opt.pyfurther, and if you do, let us know on the etherpad!
Bonus Note
Sometimes when optimizing code, you can encounter situations where your optimized code only runs faster in larger workloads, often optimizations employed may require the packages to do additional setup due to parallelization happening underneath or perhaps some memory wrangling needed underneath. Whatever the reason it may be, when benchmarking, profiling and optimizing your code it’s important you test the code under small and large workloads. Generally most optimize for the larger workloads rather than the smaller workloads, usually the extra setup cost for small workloads is worth it in comparison to the time saved on large workloads.
Key Points
After a while you’ll remember some of these optimization things and do them by default (esp, NumPy things)
Without profiling you are just guessing at what the problems is
Know when to stop