What is HPC
Overview
Teaching: 15 min
Exercises: 15 minQuestions
Isn’t an HPC just a really big desktop computer?
What facilities can I access and how?
Objectives
Compare and contrast HPC and personal computer hardware, software, and use
Understand what facilities are available in Australia
 HPC resources for this workshop are provided by The National Computational Infrastructure NCI.
HPC resources for this workshop are provided by The National Computational Infrastructure NCI.
What is High Performance Computing?
High Performance Computing (HPC) integrates systems administration and parallel programming into a multidisciplinary field that combines digital electronics, computer architecture, system software, programming languages, algorithms and computational techniques (wikipedia).
HPC can also refer to the system itself rather than the field. It might be easy to think of an HPC like a scaled up version of your own computer or a cluster of desktop machines all hooked together, however most HPC are far more complex (and powerful) than that.
A supercomputer or HPC has specialized hardware and software and a team of people whose job it is to ensure that the system runs without failure. Unlike your own computer, the most expensive part of running an HPC is not buying the hardware. Electricity use (primarily cooling) can exceed the purchase price of the hardware within a few years. On top of this there is the cost of software licenses, software and hardware support, and of course the salaries of the people who maintain the system. Given this large cost of ownership, the operators of an HPC will want to ensure the best value for money by having as little down time as possible, and as much of the resources being used when the system is up. Many of the choices about how the system is organized are therefore best understood with the high level goal of “always available, always working”.
HPC vs desktop computers
Aside from the hardware differences (discussed below), the main difference is that your computer is just for your use. When you step away from your computer it will become idle waiting for you to return. Even when you are using your computer to browse the web or write emails, most of the hardware is not being used to it’s full capacity. Full screen, high intensity gaming can really give your computer a work out, pushing the compute, RAM, and maybe disk use to the maximum, but you personally cannot (and should not) sustain this activity 24/7. You might allow your computer to sleep or turn of when not in use to save some power. Suffice to say, that your computer has a lot of capacity to do work, but mostly it just renders web pages. This idle nature does not align with HPC’s goal of “always available, always working” so they are not operated this way. Any time an HPC resource is not being used is time / energy / money that is being wasted, and all HPC facilities will work to reduce this waste by maximizing use.
A shared use system is implemented such that many people can use the HPC resources at the same time. Not only can multiple people log into the system, but they each must plan the work that they will do and the resources that are required. One does this by submitting a computing job to a scheduler which will run your job once resources are available. The scheduling system figures out the most efficient way to complete all the work by minimizing the amount of resources (CPUs, RAM, GPUs, etc) that are unused.
HPC centres try to strike a balance between how much resources are made available (how much hardware to buy and run) and the amount of work that people need to get done. If you have too much work to do, the users will have to wait a long time before they get results, and if not enough work is available, then there will be wasted time/money in the form of unused computing resources.
What HPC resources are available to me?
As an astronomy researcher in Australia there are a number of systems that you can have access to as noted in the table below.
| System | Kind | Access | Notes |
|---|---|---|---|
| Pawsey | HPC cluster | WA based researchers | Annual call for applications |
| NCI | HPC cluster | Australian researchers | Annual call for applications |
| OzSTAR | HPC cluster | Australian astronomers | Rolling / tiered applications |
| Local cluster | ? | People at your institute | Varied levels of resources and support |
| Azure / GCloud / AWS | Cloud computing | Anyone with a credit card | On demand computing as a service |
Now that we have some understanding of the high level HPC system and goals, lets dig into some of the details.
Hardware
Most HPC systems have a layout something like the following:
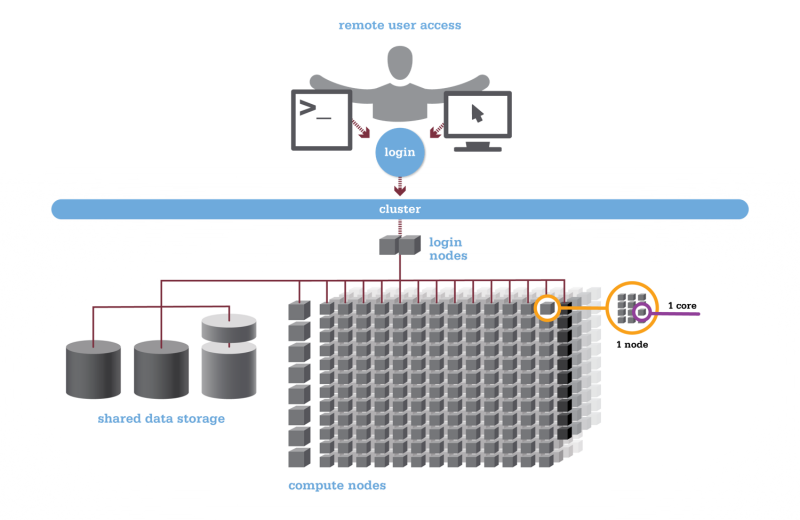
Different nodes
Typically you will log into one of a small number of login nodes via ssh. These nodes are not for doing any processing or work on, but are for you to write scripts, submit jobs, view the progress/status of your submitted jobs, and view the results of your work. These log-in nodes usually have similar hardware spec to a desktop machine (CPU/RAM wise) but will have have access to various shared file systems.
There are then compute nodes which are where all the work is to be done. These nodes typically have a large cpu or gpu count, a large amount of RAM, and possibly some super fast attached storage, in addition to being attached to the shared file systems. Depending on the HPC center there may be a range compute nodes available with different hardware setups and different intended uses. For example, some of the nodes can be optimized for network and I/O rather than computing, making them the ideal place to transfer data into or out of the computing facility. These are often referred to as data mover nodes. Another common type of node configuration is one with a very large amount of RAM, which is optimized for data visualization, and will allow people direct login access to explore their data sets. These are typically referred to as visualization nodes.
Storage options
The following storage locations are often used at an HPC:
A home directory that users will see when they log in.
This is for storing configuration files (think .bashrc, or my_prog.config) that software need to reference when they run.
These directories will be mounted on all systems, will have a slow I/O performance, and a small storage quota.
Your home directory is usually backed up.
A scratch directory that acts as a temporary storage location. This directory will be optimized for fast I/O and provide a large (or unlimited) quota. This directory is not backed up, and usually has a purge policy such that old or unused data is deleted on a regular basis. The scratch directory is not for storing things that you care about on a long term basis.
A storage directory that acts as a longer term storage location. This directory will have good I/O speeds, but not as good as the scratch area, and have a user or group quota smaller than on scratch. This space will usually be backed up and is where users should store the data that the need to keep for a long time.
All of the above storage locations are usually access via a POSIX file system interface. This means that they will look like regular drives/directories and you can read/write/copy/move files as you would on your own machine.
An archive location where users can store data for extended periods of time. An archive typically has a very slow I/O performance but a very large quota. Copying files in/out of an archive will usually involve storing your data in some intermediate location, either for the archive manager to pick up and store, or for you to copy to a location where you will process the data.
All of the above storage options are provided by storage arrays that are physically separated from the compute nodes, but joined via an interconnect system (a fast network of some description).
An additional type of storage called attached storage is sometimes available. This is usually an exceedingly fast type of storage medium (eg NVMe) which is attached to a compute node to provide the fastest possible I/O performance. This type of storage is faster than scratch, but smaller in size. Attached storage is most useful for I/O heavy applications as it will reduce the amount of time spent waiting for reads and writes to occur. Attached storage is typically ephemeral meaning that it will be empty when you start your work, and then deleted when you finish. It is therefore necessary to copy data to the attached storage at the start of your work, and then move it to a safe location (eg a storage/archive) when you finish.
Interconnect
Your desktop computer or laptop has few enough components which are all physically close to each other to allow the compute and storage to be directly connected. In an HPC facility, the computing and storage systems are usually physically distinct. The compute nodes are stored in different racks or clusters meaning that they cannot directly connect to each other. For this reason it is necessary for an HPC facility to invest in a network type system for transferring information and data between the different components. This is typically referred to as an interconnect.
Logically, you can think of the interconnect as a local network, however physically there will be multiple different networks, with different technologies being used to meet the various needs. The network that communicates between different compute nodes needs to be able to work at the smallest possible latency but not necessarily with the largest bandwidth, while the connection between a compute node and a storage system would be optimized for bandwidth rather than latency.
Clusters
Some HPC facilities partition their hardware into clusters depending on the user base, intended use, or hardware architecture. These clusters are groups of computing nodes which have a high amount of connectivity within a cluster, but are not well connected with other clusters. They different clusters act as different HPC systems, except for the fact that they may be connected to the same storage systems.
The cluster that we’ll be using for this workshop is called Gadi (“gar-dee” meaning to search for in the language of the Ngunnawal people), and is physically located at the NCI on the ANU’s Acton campus.

Software
The most important piece of software for users to know about is the work scheduler. The work scheduler is responsible for taking all of the work requests from all users, analyzing the resource requirements, scheduling where and when the jobs should be run, and then running those jobs. Commonly used schedulers are SLURM and PBS.
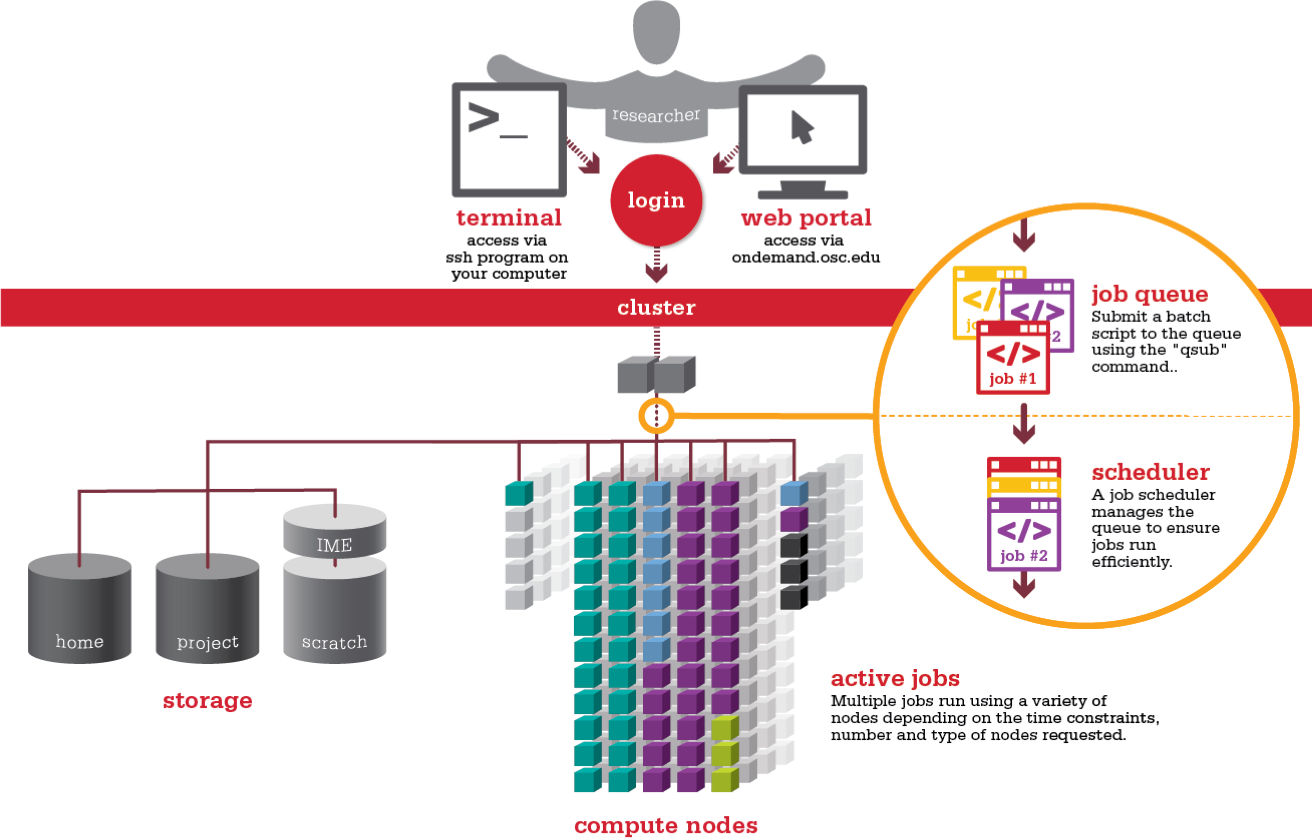
Each user or project may have a different set of software that they require for their work. It is unfeasible for an HPC facility to have all these software installed at the same time, especially because different versions of the same software may be required by different groups. To manage the large and diverse software requirements of the users a system of software management is needed. Upon login a user will have a very minimal set of software available to them (the job scheduler, a shell, and some editor to make job scripts). If more software is required then it has to be loaded using a module or environment management system. The HPC facility will have already installed a large number of software packages and version for use, but it is also possible that users can build their own software packages for personal use, or create a module/environment for others to use.
Some software packages are not designed to work on an HPC, or may have software dependencies that are not or cannot be provided by the HPC systems administrators. In such cases is it often simpler to build the software that you need inside of a container and then run your workflow within that container. Docker is a containerization system that is commonly used on personal machines where you have root access. On an HPC however you will likely need to use Singularity instead.
Key Points
HPC is more than just lots of desktops joined together
Multiple users share the system and run jobs via a queue scheduler